AIR | AI Recruiter
Superhuman
recruiting intelligence.
Conversational voice interviews, resume matching & stack ranking, customizable scoring frameworks, and enterprise-scale assessments in 16+ languages — reducing time-to-hire by 80%.

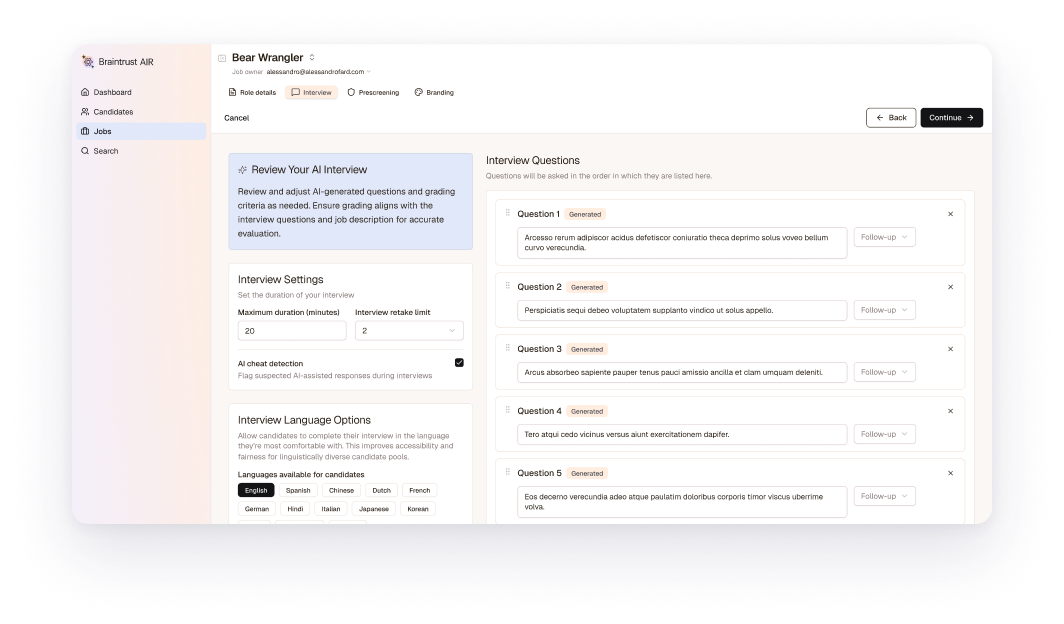
 AI Interview Agent
AI Interview Agent AI Recruiting
AI Recruiting Video Interviewing
Video Interviewing Recruiting Automation
Recruiting Automation SOC 2 Certified
SOC 2 CertifiedFrom application to
ranked, verified talent.
Five fully automated steps. Zero recruiter coordination required until you're ready to interview.
Try AIR for yourself
Experience AI-powered interviews firsthand. Access live demo sessions across 10+ roles and industries.
Access Demo InterviewsScreen smarter. Hire faster.
AIR conducts enterprise-scale AI voice interviews — and delivers structured scorecards to your ATS automatically.
Book a Demo →Trusted by recruiting teams everywhere
Hear from talent leaders who've transformed their hiring with AIR.
“AIR cut our screening time by 85%. We went from 3 weeks to 2 days for initial candidate assessments. The conversational interviews feel natural and candidates actually prefer them over phone screens.”
“We evaluated 6 AI interviewing platforms. AIR was the only one that could handle our volume — 2,000+ interviews per month — without quality degradation. The scoring consistency is remarkable.”
“Our candidate NPS went from 32 to 78 after implementing AIR. Candidates love the flexibility of interviewing on their own schedule. The AI adapts to each person naturally.”
“Hiring 500+ nurses per quarter was a nightmare. AIR screens candidates 24/7, conducts initial interviews in 16 languages, and our time-to-fill dropped from 45 to 12 days.”
“We were paying for resume screening, skills assessments, phone screening, and scheduling tools separately. AIR replaced all of them. ROI was positive in the first month.”
“Last holiday season we needed to hire 1,200 warehouse and CS roles in 6 weeks. AIR handled all initial screening and interviews. We did it with the same team size as when we hired 400.”
Join leading enterprise teams using AIR.
Reduce time-to-screen by 80% while improving candidate experience and consistency.
Book a Demo →FAQ
Transform your recruiting
See AIR in action — conversational voice interviews, customizable scoring, and enterprise-scale assessments.