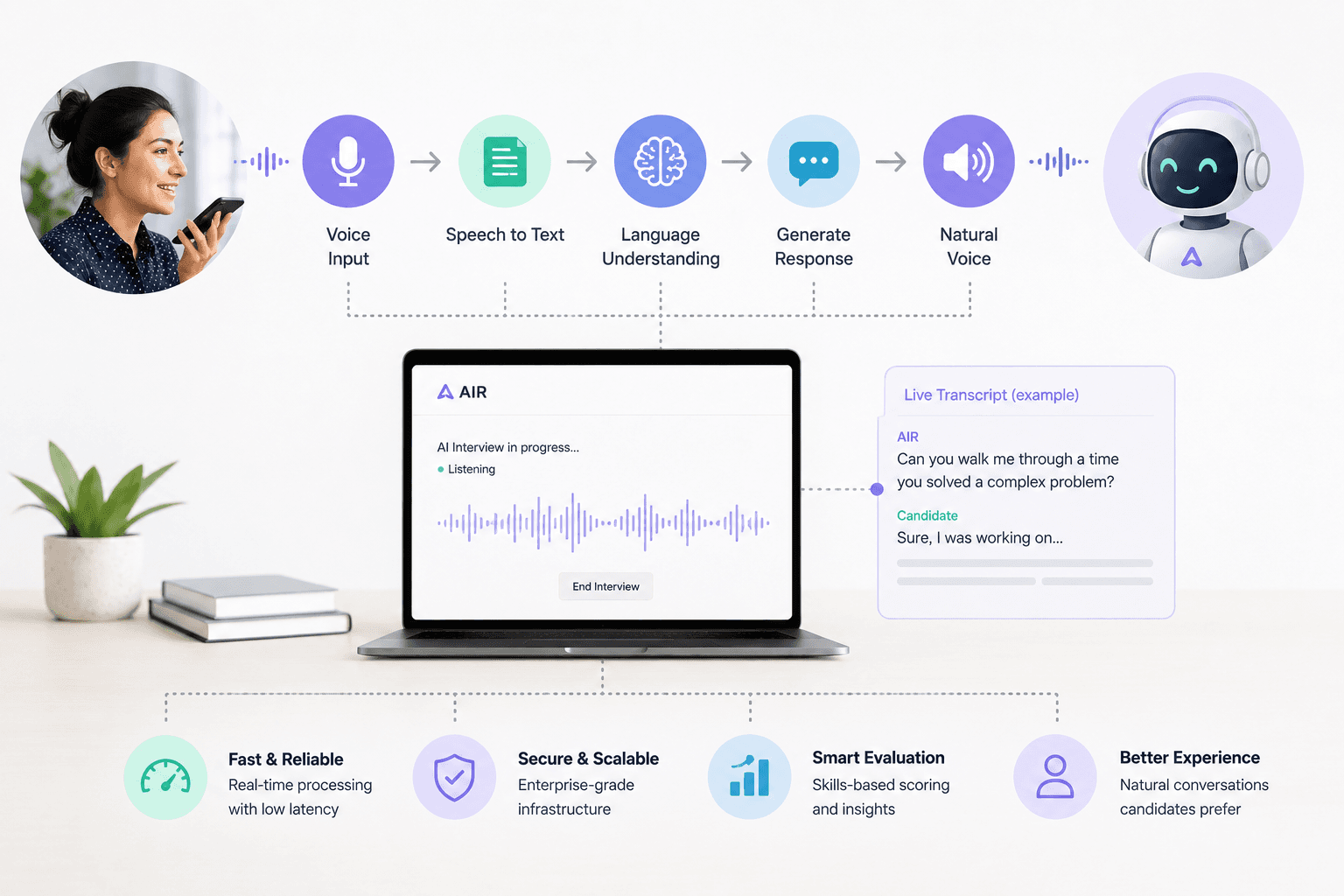
When the Braintrust engineering team set out to build AIR, the goal was conceptually simple: create an AI that could conduct a human-quality interview over video. But the technical execution required to achieve true conversational fluidity — without awkward pauses, hallucinations, or rigid decision trees — presented a significant infrastructure challenge.
Here's a look at the core technical architecture of a modern conversational AI video interview tool, and why building one from scratch is exponentially more difficult than wrapping a simple API call around ChatGPT.
The Latency Challenge
The most critical metric in conversational AI is latency. In a human conversation, the accepted gap between one person finishing a sentence and the other beginning is roughly 200-500 milliseconds. If an AI takes 3 seconds to respond, the candidate thinks the connection dropped, says "Hello? Are you there?" — and the entire conversational flow breaks down.
To achieve human-level latency, AIR relies on a deeply optimized pipeline. When a candidate speaks, their audio is streamed in real time to an ultra-fast Speech-to-Text model. We don't wait for the candidate to stop speaking before beginning transcription — the model uses endpointing to detect natural pauses and streams partial transcripts immediately to our LLM orchestration layer.
LLM Orchestration and Context Management
Once the STT engine generates text, the LLM must instantly decide what to say next. This is where simplistic chatbot wrappers fail. An interview isn't a series of isolated Q&As — it requires maintaining deep context over a 20-minute conversation.
The LLM juggles multiple directives simultaneously: ensuring the candidate is answering the specific competency being assessed, deciding whether to probe deeper based on the previous response, maintaining a warm and professional persona, and managing time allocation across the full interview. A specialized orchestration layer injects the behavioral rubrics and ongoing transcript history into the prompt context window in real time, allowing the AI to dynamically adapt its conversational path.
Voice, Video, and Empathy
Once the LLM generates a response — often streaming the first few tokens before the full sentence is complete — it goes to an advanced Text-to-Speech engine with natural intonation, breathing, and prosody. The goal is a voice that sounds warm and genuine, delivered through a live video interface that mirrors the experience of talking to a real person.
Semantic Scoring Without Hallucination
The grading happens in a completely separate, isolated computational process — not the same LLM instance that conducted the conversation. A dedicated evaluation pipeline takes the final locked transcript and scores it against strictly defined JSON schemas representing the core competencies of the role. This deterministic approach ensures 100% auditable, bias-free scorecards for every single candidate — while hiring managers also receive video recordings of each interview for their own review.
For engineering teams stress-testing these capabilities, you can try AIR for yourself and experiment with edge cases — low-bandwidth connections, intentionally ambiguous answers, rapid topic changes — to see how the system handles real-world conversation complexity.
